This is not the kind of blog post I will typically be writing, however I have lately been tinkering with the DXR API as I intend to implement path tracing (and maybe Bidirectional path tracing :O ) using the new API on the GPU. In the process I found myself on a tangent about the different ways to get contents from the GPU to the display, and the pros and cons of each. This post will talk about present latency, fps, Desktop Windows Manager, and waitable swap chains. I will not go into detail about the impacts of multiple backbuffers in the swapchain, nor the impact of having several command allocators as the post will be too long.
How do monitors work?
Monitors update in a scanline (LCD included), this is done by streaming data over the display link (DVI or HDMI or DP), and as the digital data arrives to the monitor, the monitor uses its DAC (Digital to Analogue Converter) to provide the analogue response for the monitor. Once a pixel is given a new analogue signal, the response time of the pixel determines how fast it will update to the new provided color. In an LCD display, pixels never turn off, they retain the previous color they had until a new color signal is issued to them. We can see the scanline effect in the following video of an LCD display captured in slow motion:
https://youtu.be/3BJU2drrtCM?t=269
To read about how the actual analogue signal produces an image on the monitor, you may read the following article:
https://www.rtings.com/tv/learn/lcd-vs-led-vs-plasma/how-they-work
How do we get information to the monitor?
This it the interesting part that I found myself investigating a lot after working with DX12, and is what this post will explore more in depth. Before we continue, it is best to get some terminology out of the way:
Backbuffer: A backbuffer is a buffer that serves as the render target of a GPU. An image is rendered into a backbuffer, and the contents of that are then used to bring a picture to the monitor. An application can have several backbuffers.
Frontbuffer: A frontbuffer is the specific backbuffer that is currently being used as the resource for which the monitor will pull image data from. Only one of the backbuffers can be a frontbuffer at any given moment.
SwapChain: A swapchain is the graphics API object that holds the backbuffers. The key thing to note about a swapchain is that calling SwapChain::Present will queue up a backbuffer to act as a frontbuffer. Thus in order to get a backbuffers contents onto the display, we call the Present function. The call to this function by the CPU is asynchronous. For this blog post we will assume a flippable swap chain, as in 2 or more backbuffers, that the swapchain will flip between when presenting.
CommandQueue: A command queue holds a series of instructions for the GPU to run. The GPU will run these instructions in the order that they exist on the command queue. When a swapchain is made, it must be associated with a command queue, the Present function will actually queue instructions into the command queue that the swapchain is associated with. It is possible to have several command queues, but that is out of the scope of this post, for now let us assume a single primary command queue.
CommandList: A command list records a list of commands that are to be queued to the GPU. The CPU can build a command list at any point using any thread, and then can submit the command list to a command queue using the function ExecuteCommandLists. Note that ExecuteCommandLists is asynchronous, that is, none of this work is done on the GPU until the GPU is ready to consume instructions from the command queue that the command list was queued to execute on.
CommandAllocator: A command allocator is the memory that backs a command list. A command list must be coupled with a command allocator when it is reset. A command allocator can be associated with many command lists over its lifetime, but only one at any given moment. It is also unsafe to reset a command allocator while its instructions are still pending in a command queue, as the command queue reads the instructions from this memory, and modifying it is unsafe.
With the above terminology out of the way, we can discuss the rendering process a bit. An application will use the CPU to build a command list associated with a command allocator. It will then call ExecuteCommandLists using that command list and the command queue. Finally the CPU will also call Present on the swapchain associated with that command queue. Notice that both of these operations were asynchronous, so no GPU work has yet to begin. The CPU has simply told the command queue to run the command list and then present the contents.
Assuming there is no prior work on the GPU. The GPU can commence running the instructions immediately, and then finally it will reach the point where it will call Present. This is where there are several possible courses of action. In the simplest case where we assume the monitor is streaming data directly from the frontbuffer (which is one of our applications backbuffers), the present call can flip which backbuffer is the frontbuffer, and the monitor will now stream from this new buffer. The moment the GPU is completed with a frame, the monitor will pull data from that frame, regardless of what scanline the monitor is on. In this very simple case we will have the minimum possible input latency (from here on out, I will refer to input latency as present latency, as input latency has other external factors associated), but we will have screen tearing. The following link does a good job of showing this kind of tearing: https://www.anandtech.com/show/2794/2
The alternative is that we have some synchronization going on. For this post I will ignore adaptive vsync (such as freesync or gsync), and will focus on vsync. Enabling vsync in an application will control when the swapchain can actually flip the frontbuffer. In the unthrottled case, we could flip the frontbuffer whenever we wanted, however we can be smart about this, and only flip the frontbuffer during a vertical blank (VBLANK), and in this case there will be no tearing. This is because the frontbuffer is not flipped while the monitor is streaming data from it, and thus the first scanline for each displayed frame will start with a fresh frontbuffer. We can reason that, any kind of waiting will obviously incur present latency. Lets say I call present, and the VBLANK is 10ms later, then the data that I am presenting is now 10ms old.
The impacts of vsync on present latency will depend on whether the application is in windowed mode or in full screen, and also on whether the swapchain is initialized a a waitable object (more on this later).
Windowed vs Fullscreen
In Windows Vista/7/8/10 there exists a process called “Desktop Windows Manager” (referred to as DWM from now on). The DWM is a process that uses the backbuffers presented by all the running applications, and composites them together into a final image that will be placed in a frontbuffer. In this case, the applications backbuffers do not directly turn into frontbuffers, but instead backbuffers are fed to the DWM. This composition allows Windows to do various visual effects, like layering applications on top of each other, giving a preview popup when you hover over an open application in your bottom bar, giving the overlay for alt-tabbing etc.
The way the DWM works in practice is that all the applications present backbuffers, and then after the vsync, DWM will pick up the most recently completed backbuffers from all the applications and then use the next frame interval to composite everything into its own backbuffer. Then during the next VBLANK, the DWM will present its own backbuffer which will become the frontbuffer the monitor will consume from. I would like to emphasize that, in this case the DWM is itself vsynced. The DWM itself has a swapchain, and it will only flip the backbuffers around during the monitor’s VBLANK, and so there is no tearing. Also notice that with the DWM, there will be two sources of latency. One source is the fact that flips only occur during a VBLANK, so there is a waiting period there after DWM has completed the composited image. The other source is the fact that DWM does not pick up the backbuffers that applications present until a VBLANK, and only after that does DWM begin compositing. Here is an example:
T=0ms, Application builds command list
T=1ms, Application executes command list in a command queue
T=3ms, GPU is finished rendering into backbuffer and frame is ready to be consumed
T=17ms, at this VBLANK, DWM wakes up, takes the latest backbuffer and begins composition
T=18ms, DWM is done compositing and the frame is complete in its backbuffer
T=34ms, at this VBLANK, DWM can flip the backbuffer it previously completed to become the frontbuffer that the monitor will stream data from
We can see based on the above timeline that in this case, the presence of DWM added around ~31ms latency. In contrast if we were operating in exclusive full screen mode without vsync, then at T=3ms the application would have been able to flip the backbuffer to become the frontbuffer. This is because in exclusive full screen mode, DWM is bypassed and the application’s backbuffers directly become frontbuffers, and the application is free to flip the buffers whenever it wants (keep in mind that we cause tearing like this, whereas with DWM it is not possible to have tearing).
Notice how in the above scenario, if Event 1 & Event 2 took a combined time of 16 ms (that is that GPU completing rendering into the backbuffer occurs at T=16ms), then the latency added by DWM is ~17ms which corresponds to 1 frame interval on a 60hz monitor. Thus we can say that at minimum, DWM adds 1 frames worth of latency. In practice, it will likely be slightly more. Usually a game is likely running at a fps higher than the refresh rate of the monitor. In this case, it is important to point out that DWM will pick up the most recently presented backbuffer that has been completely rendered into by the GPU. Let us look at a sample timeline:
T=0ms, Application builds command list 1
T=1.5ms, Application executes command list 1 in a command queue
T=4.5ms, GPU is finished rendering into backbuffer and frame is ready to be consumed
T=4.5ms, Application builds command list 2 for a new frame
T=6ms, Application executes command list 2 in the command queue
T=9ms, GPU is finished rendering into backbuffer and frame is ready to be consumed
T=9ms, Application builds command list 3 for a new frame
T=10.5ms, Application executes command list 3 in the command queue
T=13.5ms, GPU is finished rendering into backbuffer and frame is ready to be consumed
T=13.5ms, Application builds command list 4
T=15ms, Application executes command list 4 in the command queue
T=17ms, at this VBLANK, DWM wakes up, takes the latest backbuffer with the render of command list 3 and begins composition
T=18ms, GPU is finished rendering into backbuffer and frame is ready to be consumed
T=18ms, DWM is done compositing and the frame is complete in its backbuffer
T=34ms, at this VBLANK, DWM can flip the backbuffer it previously completed to become the frontbuffer that the monitor will stream data from
In the above situation, command list 4 was queued to do work on the GPU, however the GPU was not done rendering that frame in time for the DWM to pick it up, and so the frame produced by command list 3 is used instead. Command list 3 was built at 9ms, and finally made it on screen at 34ms, and so we can observe a latency of 25ms.
Using a tool called PresentMon, I took a capture of World of Warcraft running in DX12 with windowed mode:

In this case, composed flip means using a flip swapchain where DWM is composing the results to produce the frontbuffer. At ~144 fps we have ~24ms of latency (my monitor is 60hz). This is inline with the example we drew above. At a minimum the present latency is the sum of a frame interval and the time it takes to produce the frame. I say a minimum because it can be slightly more, depending on how close to the VBLANK the frame finishes at, if a frame takes 5ms to produce, and completes 4ms before the VBLANK, it will still be the frame that DWM will pick up, however it will already be 9ms old. On the other hand if the frame finishes 0.1ms before the VBLANK, it will only be 5.1ms old before DWM picks it up. For that capture of WoW, it took 6.93ms to produce the frame, and 16.67ms for a frame interval, giving 6.93 + 16.67 = 23.6ms, which is slightly short of the reported 24.35ms.
To further visualize this (and further discussion in this post), we will use a tool by Intel: https://software.intel.com/en-us/articles/sample-application-for-direct3d-12-flip-model-swap-chains
In this tool, the bottom row is the CPU timeline for frames, the 2nd row (from the bottom), is the GPU timeline, the following rows going up are the present queue (there can be several rows here), and the top most row is what is actually being displayed on the monitor. The following image is a capture of the tool simulating an experience at 240fps:

There is a lot going on in this capture, but we need only focus on a few things. Each vertical black line represents a VBLANK. If we look at the leftmost side of the image, we see the CPU builds a command list (the leftmost one is red), then the GPU executes that command list, and then the frame is queued into the present queue. In the leftmost interval, the frame at the top of the present queue is blue, this is a frame that was built by DWM before the first VBLANK of this screenshot, and is what will be displayed on the monitor after the VBLANK. We can see that whatever was rendered into the red backbuffer is discarded (triangles in the present queue means the contents were discarded). The reason for this is because a more recent frame is built in the blue backbuffer. This blue frame is also discarded because the framerate is so high, that another frame is completed in time in the red backbuffer (the swapchain is alternating between the 2 backbuffers). We see that the CPU builds a blue frame before the VBLANK, but the GPU is not done executing the work for this command list before the VBLANK, and so the DWM consumes the red backbuffer upon waking up. You can notice that the red backbuffer is now the one at the top of the present queue in the 2nd interval, and will be on screen for the 3rd interval. This whole process yields a reported present latency of ~25.5ms (it is an average), and is a fairly accurate depiction of what happened in the World of Wacraft process.
For completeness, it is worth showing what the situation looks like when running in borderless windowed mode and bypassing the DWM. Before showing pictures, I would like to introduce some more terminology. If an application is covering the entire viewport, then DWM (at least in Windows 10 with DX12, I am unsure about DX11), is able to recognize this and engage in a mode called “Independent Flip”. Notice how earlier, PresentMon reported that we were running in “Composed Flip”. Independent Flip is a mode in which DWM does not composite anything, the backbuffers of an application directly become the frontbuffers that the monitor reads from, and all the DWM does is execute the flip during the VBLANK. In Independent Flip, an application is locked to a frame rate that is a multiple of the refresh rate. The reason for this is that once an application queues up a present, the backbuffer now belongs to the monitor and cannot be rendered into. Furthermore, whatever backbuffer is currently the frontbuffer, belongs to the monitor for the entire frame interval and also cannot be rendered into. Thus assuming we have 2 backbuffers in the swapchain, if one of them is held by the monitor to stream from, then we can only render into the remaining backbuffer, and the moment we queue the present with that backbuffer, we cannot use it either. Thus with 2 backbuffers, the maximum fps is 60. This scales with the number of backbuffers, and 3 backbuffers gives a maximum fps of 120.
I wont go into further detail on Independent Flip because in practice games do not really want to be using this flip mode. Instead, it is best to use a mode called “True Immediate Independent Flip”. This is a mode that doesnt just remove compositing, but removes the DWM entirely. That means that the application itself is responsible for flipping the frontbuffer, which allows it to present at an unthrottled rate (which is of course vulnerable to tearing). To run this mode, the swapchain must be initialized with tearing enabled, and the call to present must have the flag DXGI_PRESENT_ALLOW_TEARING. This flag has a value of “512” and so we can see above in the PresentMon capture of WoW, that they do in fact allow the application to enter True Immediate Independent Flip. We can confirm this with a capture of WoW in full screen using PresentMon:
 World of Warcraft in True Immediate Independent Flip Mode
World of Warcraft in True Immediate Independent Flip Mode
We see that the PresentMode reported is Independent Flip, and the PresentFlags of 512 indicate that the application can run in True Immediate mode. In this case the MsUntilDisplayed is the present latency, and we can see that it matches the MsUntilRenderComplete column (directly to the left of MsUntilDisplayed) perfectly. This means that as soon as a frame is complete, we put it on screen, and so the only present latency is the latency of actually rendering the frame itself. This is the absolute minimum possible latency that an application can achieve. This same latency was possible with full screen exclusive (different from borderless windowed), however alt tabbing from a FSE (full screen exclusive) application is usually very slow. True Immediate Independent Flip brings the best of both worlds, where we have the minimum present latency possible while still being able to alt tab quickly. Its worth noting that not all games engage in Independent Flip when the application covers the viewport, I am not sure about the exact criteria (it might require a certain version of DirectX). An example of this is Overwatch. When running Overwatch in borderless windowed mode, PresentMon captures the following:
 Overwatch in borderless windowed (DWM composition)
Overwatch in borderless windowed (DWM composition)
I know that Overwatch runs on DX11, but I do not know more than that. However it is clear that we are not using hardware composition, and the DWM is still in charge (Copy with GPU GDI means we are using a blit model, not covered in this post and not possible in DX12). We see that a bunch of frames are discarded (dropped), and DWM will only pick up the most recent one to display on the monitor. The present latency hovers between 28ms and 40ms, which is around what we would expect based on earlier findings. Running Overwatch in FSE gives us the expected results:
 Overwatch in full screen exclusive
Overwatch in full screen exclusive
Waitable Swapchains
SwapChain::Present is async on the CPU, however it is serial on the GPU and is only triggered after the commands in the command queue before it are finished. The moment the present is executed on the command queue, then the waitable swap chain is alerted of this, and the event that the CPU was waiting on is triggered. Likely this is implemented with fences behind the scenes, but I have yet to find conclusive information on the implementation of Present so I wont go into further detail. There is one extra parameter of a waitable swap chain that must be specified; maximum frame latency. Maximum frame latency is a value that describes how many presents the waitable swap chain can have queued up at once.
Waitable Swapchain – Windowed
Let us look at a windowed case using waitable swap chains. In the Intel application, a yellow bar in the CPU timeline means that the CPU is waiting on the swap chain event that signals that the GPU has reached the present instruction in the command queue. The following is such a capture:

Here, when the CPU builds the command list for a given backbuffer, it waits until the GPU is done rendering into that backbuffer, and then builds the command list to render into the next backbuffer. This is because after building a command list, the CPU waits on the swapchain, and only once the GPU finishes rendering that command list, does the command queue signal to trigger the swapchain event. Notice that we can render into the backbuffer for the frame associated to the one that is currently displayed on monitor. This is because we are running in composite mode, and the buffer the monitor is holding is actually the buffer that DWM composites into and thus is not the same as the backbuffer that we write into.
Disabling the waitable swap chain in favor of a regular swap chain leads to increased present latency. This is because the moment that the GPU is done rendering into a backbuffer, the CPU builds the command list for rendering into that SAME backbuffer, whereas in a waitable swap chain, the CPU at this point would build the command list for rendering into the NEXT backbuffer (this is important to understand, think about this sentence and look at the above image and below image until you agree). The backbuffer will still take the same amount of time to become available (it must go through the DWM which will use it to composite and then release it), however now the CPU has built the command list for it earlier than in the case of a waitable swap chain. As the command list was built earlier, it is more outdated by the time the results are on screen, and so present latency will go up. The below image shows this (Blue indicates time the CPU is waiting on the GPU):

Clearly a waitable swap chain in this case has less present latency. However, nothing is for free. By waiting on the swap chain, and having a maximum frame latency of 1, we have reduced some of the parallelism between the CPU and GPU. You may notice how in the waitable swap chain case, the work between the CPU and GPU looks very sequential, and that despite having a GPU fps of 77 and a CPU fps of 102, the total fps is 45. This is because the two devices are forced to run almost serially due to the waiting. This is in contrast with the case where we do not use a waitable swap chain, which has an fps matching the GPU fps (which is where the bottleneck is). In this case we are trading fps for present latency.
We can regain this fps lost in the waitable swap chain case by using a maximum frame latency of 2, however we pay back for this with present latency:

In the case of maximum frame latency of 2, we are allowed to have 2 built frames before we must wait on the swap chain. This means that we effectively able to buffer an extra frame and the CPU and GPU are no longer working serially. However, buffering in this manner is what introduces the extra present latency compared to a maximum frame latency of 1. This should be familiar. Engineering is always about tradeoffs, and very rarely is something free. The question now becomes, in what cases might we benefit from a waitable swap chain? Because if there were to be no difference between a regular swap chain, it would be a rather useless addition. Based on the above, we can reason that, if the combined work time of the CPU and the GPU produces acceptable fps, then the tradeoff is likely worth it. Most users have monitors with a 60hz refresh rate, producing fps higher than this is a complete waste unless it contributes to reducing present latency. In the case where the application can present at an unthrottled rate and tearing is allowed, then higher fps results in reduced present latency. However when playing in windowed mode, the DWM is responsible for presenting to the screen and so higher fps is not always the best approach for minimizing present latency.
Consider the case below:

Here we present at an unthrottled rate, the CPU has little work and most of the work is on the GPU, which is running at an fps of 91. The total fps is 87 and the present latency is 46ms. In this case, clearly the combined total of the GPU and CPU work is still less than ~17ms, and so perhaps this is a situation where a waitable swap chain might net us some gains.
Enabling a waitable swap chain gives us:

We see that indeed, we can trade a bit of fps here and profit in the form of present latency. The loss in fps here will not be noticeable on a 60hz monitor and in turn the application is slightly more responsive. For a more practical situation worth analyzing, we can consider when a user is running the application with vsync. Likely the application will now be locked to 60 fps (on a 60hz monitor), but the time it takes to do the combined CPU and GPU work is probably less (otherwise there is no reason for the user to enable vsync).
Without a waitable swap chain and vsync on, we might see an application perform like the following:

Here we can see that the CPU is building a command list significantly before the GPU has the buffer available to do work in. The top row of the present queue is the point at which DWM is holding the backbuffer for composting, and when it is released, the backbuffer is free for the GPU to render into (notice that whatever color buffer is being displayed on the monitor, is the buffer the GPU will render into for that frame interval, because the DWM just released that buffer on the previous VBLANK). We can see clearly that the combined work of the CPU and GPU will not exceed the 16.66 ms that we must adhere to. On the other hand, we have a significantly high present latency, because the CPU is building the command list way before the GPU has the resources available to do that work. This sounds like the ideal case to benefit from a waitable swap chain! Let’s take a look:

Clearly, in no loss for frame rate, we obtain much better present latency. This makes sense, because the command list for a given backbuffer is built in the frame interval directly before the compositor will access it, and thus holds more recent information.
Waitable Swapchain – Borderless Window Full Screen
Finally, it is worth looking at the case of borderless window full screen, which most gamers are likely to run the application in. In this case, the present mode is independant flip, and the DWM is no longer compositing anything. We get the following result:

We have a present latency of 40ms in this case, which is rather high for most real time applications. Enabling a waitable swap chain gives us:

The present latency here is drastically better. It is clear that in the case of hardware that can run the application at above 60 fps, and vsync on, that a waitable swap chain is a significant win. In fact, I believe that this is the shortest present latency possible with vsync enabled (without vsync the present latency is the time to build the frame, as we established above). You can also clearly see here that the DWM compositor is no longer involved, a backbuffer is displayed on screen the VBLANK after it is completed by the GPU, whereas composition would consume an extra frame before displaying it on screen.
For completeness however, it is important to point out that using a waitable swap chain with a maximum frame latency of 1 can leave you vulnerable to fps spikes, or in certain cases can even cause a lot of harm. Consider the following example:

Remember that the CPU and GPU do work sequentially in the case of a maximum frame latency of 1. First the CPU builds the command list, then the GPU renders it, however if the GPU does not finish in time for the coming VBLANK, and just barely misses it, then it must wait for the next VBLANK before the contents of the backbuffer make it on screen. We see this above where some frames last on the screen for twice as long as other frames. This is because the total time of the CPU and GPU took slightly longer than 1/refresh rate, and so a frame is missed completely. In cases like this, the effective fps becomes half, where we see above that GPU fps was 76 and CPU fps was 170, but total fps is 30. This will also cause the present latency to double, which is counter productive to our goal of using a maximum frame latency of 1. In this case a maximum present latency of 2 will be better:

For the same present latency, we get double the fps, which will of course feel like a smoother experience to the user.
Essentially there is no one setting to rule them all. At worst, a waitable swap chain with a maximum frame latency of 2 will behave as good as no waitable swap chain. A waitable swap chain with a maximum frame latency of 1 is better if the user’s machine is able to render much faster than users monitor refresh rate. If the user does not care about tearing and will not use vsync, then for borderless window full screen, a waitable swap chain is not needed at all. As mentioned before in this post, in True Immediate Independent Flip the application can present as fast as possible with no delay on throughput, which looks like this:

Conclusion
If the user does not care about tearing, or has an adaptive refresh rate monitor with a GPU that supports it, True Immediate Independent Flip is the best approach as it will deliver the minimum present latency. If the user cares about tearing and will turn on vsync, then the usage of a waitable swap chain might present some gains, but care must be taken in determining the maximum frame latency, as it is possible to drop the users fps with no gains in present latency (the case where we had 30 fps instead of 60 fps due to missing VBLANKs). We have also pointed out the impact of the Desktop Windows Manager on present latency and hopefully made its presence intuitive via the graphical aids created with Intel’s application. What we did not cover was the impact of frame count (the number of command allocators the CPU can build command lists into), nor the number of backbuffers available to the swap chain, and how those things impact present latency and fps. We also did not cover the notion of Triple Buffering vs a Render Ahead Queue (they are different things and are often confused with each other). Perhaps the topics left uncovered will find their way into a future blog post.



































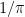
 . Radiant flux is the radiant energy emitted, reflected, transmitted or received, per unit time. It has units of
. Radiant flux is the radiant energy emitted, reflected, transmitted or received, per unit time. It has units of  . which is also known as watts.
. which is also known as watts. . Radiant flux is the radiant flux per unit solid angle. As such, it has units
. Radiant flux is the radiant flux per unit solid angle. As such, it has units  .
. . Irradiance is the radiant energy received by a surface, per unit area. As such it has units
. Irradiance is the radiant energy received by a surface, per unit area. As such it has units  .
. . Radiance is the radiant flux emitted, reflected, transmitted or received by a given surface, per unit solid angle per unit projected area. As such it has units
. Radiance is the radiant flux emitted, reflected, transmitted or received by a given surface, per unit solid angle per unit projected area. As such it has units  .
. Eq.1
Eq.1 is the out going radiance in the direction o.
is the out going radiance in the direction o.  is the out going radiance emitted by the surface. The last term is the integral of the incoming radiance weighted by the cosine of the angle between the surface normal and the incoming direction and also weighted by the BRDF. The integral is over the hemisphere oriented around the surface normal.
is the out going radiance emitted by the surface. The last term is the integral of the incoming radiance weighted by the cosine of the angle between the surface normal and the incoming direction and also weighted by the BRDF. The integral is over the hemisphere oriented around the surface normal.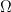 . Remember that we said that the units of radiance was
. Remember that we said that the units of radiance was  , which has units
, which has units  . If we multiply those 2 units together, we find that the
. If we multiply those 2 units together, we find that the  term exist for? Let us look at the following image:
term exist for? Let us look at the following image:
 , and in
, and in  the
the  component is the area of the receiving surface as seen by the light in the direction i.
component is the area of the receiving surface as seen by the light in the direction i. Eq.2
Eq.2 . The BRDF can be described mathematically as the ratio of differential outgoing radiance, to the differential irradiance:
. The BRDF can be described mathematically as the ratio of differential outgoing radiance, to the differential irradiance: Eq.3
Eq.3 Eq.4
Eq.4 Eq.5
Eq.5 , which means the BRDF must have units
, which means the BRDF must have units  .
. , where if light is only coming from a single direction
, where if light is only coming from a single direction  then if we also assume some constant area for the receiving surface, then the entire expression becomes a constant, where we have radiance * unit of area * unit of solid angle, which will leave us with watts.
then if we also assume some constant area for the receiving surface, then the entire expression becomes a constant, where we have radiance * unit of area * unit of solid angle, which will leave us with watts.
 so far as the function that determines the fraction of incident energy reflected in a direction. However, as stated before, the BRDF must relate incident energy (irradiance) to radiance, so it is not enough to just define the distribution of energy, we must also factor in projected area. The question now is, how do we bring projected area into our incomplete BRDF? Well, at viewing directions that are almost orthogonal to the emitting surface normal, the apparent surface area of the emitting surface from the viewers perspective is very small. In fact, the emitting surface appears the largest when viewing it from a direction parallel to its normal, and then it drops off the greater the angle between the normal and the viewing direction. However, for a given radiant intensity, the smaller the apparent area of the emitting surface, the larger the radiance. Thus radiance is inversely proportional to
so far as the function that determines the fraction of incident energy reflected in a direction. However, as stated before, the BRDF must relate incident energy (irradiance) to radiance, so it is not enough to just define the distribution of energy, we must also factor in projected area. The question now is, how do we bring projected area into our incomplete BRDF? Well, at viewing directions that are almost orthogonal to the emitting surface normal, the apparent surface area of the emitting surface from the viewers perspective is very small. In fact, the emitting surface appears the largest when viewing it from a direction parallel to its normal, and then it drops off the greater the angle between the normal and the viewing direction. However, for a given radiant intensity, the smaller the apparent area of the emitting surface, the larger the radiance. Thus radiance is inversely proportional to  , which is just 1. This matches what we know about Lambertian diffuse, that radiance is independent of viewing direction.
, which is just 1. This matches what we know about Lambertian diffuse, that radiance is independent of viewing direction. In order to reach that form, we need to go ahead and normalize the BRDF, by forcing an energy conserving constraint on it. There are many different explanations for the energy conservation constraint, I will present the one that makes most physical sense for me. If the BRDF is fundamentally a fraction of incident energy scattered in an outgoing direction weighted by its apparent area, then if we undo the apparent area weighting, we should be left with a function that gives the fraction of incident energy scattered in an outgoing direction. Thus that would form
In order to reach that form, we need to go ahead and normalize the BRDF, by forcing an energy conserving constraint on it. There are many different explanations for the energy conservation constraint, I will present the one that makes most physical sense for me. If the BRDF is fundamentally a fraction of incident energy scattered in an outgoing direction weighted by its apparent area, then if we undo the apparent area weighting, we should be left with a function that gives the fraction of incident energy scattered in an outgoing direction. Thus that would form  as our function relating incident energy and outgoing energy. Energy conservation dictates that total outgoing energy must be equal to total incident energy, where total outgoing energy is obtained by integrating the outgoing energy in all directions over the hemisphere. If
as our function relating incident energy and outgoing energy. Energy conservation dictates that total outgoing energy must be equal to total incident energy, where total outgoing energy is obtained by integrating the outgoing energy in all directions over the hemisphere. If 
 , which we can plug into our constraint above and then solve the resulting integral to find our normalization factor for energy conservation. We transform from solid angle to spherical coordinates to make the integral easier to solve, where the jacobian determinant of this transformation is
, which we can plug into our constraint above and then solve the resulting integral to find our normalization factor for energy conservation. We transform from solid angle to spherical coordinates to make the integral easier to solve, where the jacobian determinant of this transformation is  giving us the integral:
giving us the integral:
 , and since our energy conservation constraints dictates that this must evaluate to 1, it tells us that our normalization factor is
, and since our energy conservation constraints dictates that this must evaluate to 1, it tells us that our normalization factor is 